

Cognizant, a multinational technology company, is based in the United States, with its headquarters located in Teaneck, New Jersey. It specializes in business consulting, information technology, and outsourcing services. Cognizant’s inclusion in esteemed indices such as NASDAQ-100, S&P 500, Forbes Global 2000, and 500 underscores its position as one of the globe’s highly successful and swiftly expanding organizations.

Cognizant recruitment is pivotal in helping businesses modernize their technology infrastructure, reimagine operational processes, and transform customer experiences to stay competitive in an ever-evolving landscape. The company is committed to enhancing the global business ecosystem through technology, whether by reshaping the organizations the world relies on or by offering the tools and adaptability needed for personal growth and professional growth. Cognizant’s core areas of expertise encompass information technology, information security, consulting, IT Outsourcing (ITO) and Business Process Outsourcing (BPO) services. The company’s business operations are categorized into three main segments: digital business, digital operations, and digital systems and technology.
Eligibility Criteria
- Candidates should have scored over 60% in 10th and 12th grades (or diploma).
- A minimum of 60% marks in graduation is mandatory.
- There should be a maximum gap of one year after HSC (12th) but not after SSC (10th) or between semesters during graduation.
- Eligible degrees include BE, B Tech, ME, M Tech, and MCA.
- During the Cognizant selection process, candidates must not have any pending backlogs.
You can look for job opportunities in Hyderabad by clicking fresher job openings in Hyderabad.
Interview Process
Cognizant offers a compelling choice to launch your career, boasting a positive company culture and sufficient growth opportunities. It facilitates an excellent work environment that encourages skill development, benefitting both individuals and the company. This blog comprehensively explores the cognizant interview process for freshers jobs seekers and shares effective preparation strategies. Our insights are based on online research and interviews with recent Cognizant interviewees. Cognizant recruits for various roles and departments, welcoming freshers and experienced professionals. They engage in campus placements, walk-ins, and mega placement drives for freshers, while experienced hires primarily come through their career websites, HR consulting firms, and employee referral programs. Candidates who are currently looking for jobs can visit Cognizant Jobs For Freshers.
Cognizant is set to conduct recruitment processes for four distinct positions:
- GENC
- GENC ELEVATE
- GENC PRO
- GENC NEXT
Interview Rounds
Round 1: Aptitude Test/Skill-Based Assessment Test: This online assessment is conducted on platforms like AMCAT. Candidates applying for the GENC profile must participate in the aptitude test, which comprises the following sections:
- Quantitative Ability: This section typically includes questions covering Basic Mathematics, Applied Mathematics, and Engineering Mathematics.
- Logical Reasoning: This section typically includes questions related to Coding Deductive Logic, Data Sufficiency, Objective Reasoning, Data Arrangement, Coding Pattern Recognition, and Number Series Pattern Recognition.
- English Comprehension: This section typically includes questions related to Vocabulary (Synonyms, Antonyms, Contextual Vocabulary), Grammar (Error Identification, Sentence Improvement, and Construction), and Reading Comprehension.
Applicants for the GENC NEXT, GENC PRO, and GENC ELEVATE profiles must participate in the skill-based assessment test, which includes the following sections:
- MCQ – Conceptual and Code Analysis
- Coding Challenges – Coding Questions
The cognizant interview questions will typically pertain to the following subjects:
- Programming Constructs, Data Structures, Algorithms
- Database/SQL
- Web UI
Based on their performance in the skill-based assessment tests and interviews, candidates will be chosen for roles in GENC NEXT, GENC ELEVATE, or GENC PRO. To qualify for the GenC Elevate assessment, candidates should possess at least fundamental hands-on programming skills supported by evidence provided during the self-profiling process. Once candidates achieve the required cutoff score in the aptitude test/skill-based assessment test, they proceed to the technical interview round.
Round 2: Technical Interview: The face-to-face technical interview is the pivotal phase within the entire interview process. It necessitates a solid grasp of computer science fundamentals, encompassing topics like OOPS, DBMS, CN, and OS, and the ability to articulate these concepts clearly to the interviewer. Proficiency in a programming language is essential. It’s not obligatory to be proficient in every programming language, but you should have substantial experience in at least one, such as C++, Java, or Python. There’s a significant likelihood that you may be asked to write code on paper during the interview, thereby assessing your problem-solving skills. Having knowledge of the latest technological advancements is an added advantage. A foundational understanding of contemporary tech trends, like artificial intelligence (AI) and big data, is desirable. You can also expect inquiries related to your CV and the company as well.
Round 3: HR Interview: The HR interview stands as the most pivotal phase of the cognizant interview process, where many candidates face elimination. The key objective is to maintain a pleasant and confident attitude, as these interviews can be lengthy and demanding. During the HR round, the interview panel will inquire about your personality, family background, educational history, interests, internships, and related topics. It’s essential to be well-prepared to answer cognizant interview questions concerning your internships, projects, volunteer work, and extracurricular activities listed in your resume. Expect inquiries about the company as well, including its products/services, core values, founding date, organizational structure, and more. Preparation is important when it comes to HR interview questions and responses. It’s advisable to compile a list of common HR interview questions and practice your responses. Familiarize yourself with these answers, ensuring they are readily accessible. Additionally, remember to project confidence in your appearance and behavior during the interview, striking a balance between honesty and confidence. Exceptional body language can significantly impact the outcome. Cognizant interview questions asked during a HR Interview for Freshers are listed below:
- Could you please tell me about yourself?
Start by explaining why you are enthusiastic about working in that particular company. Then, extend the answer by explaining about your internships. Tell them about your responsibilities and how that opportunity helped develop your skills and abilities. Tell about how it helped you to learn the importance of the specific skills you acquired.
- Could you please tell me about your Strengths?
I believe my strengths lie in my adaptability and eagerness to learn. I consistently demonstrated my ability to acquire new concepts quickly and effectively during my academic journey. I am highly self-motivated, motivating me to take on challenges with enthusiasm and determination.
- What makes you the ideal candidate for this position?
Start by telling how your educational foundation and learning curiosity make you an ideal candidate for this position. Mentioning your academic background and how it helped you to gain a solid understanding of that relevant skills or knowledge.
- What aspects of this profession do you find personally fulfilling?
I find the potential for continuous learning and growth in this profession to be personally fulfilling. The dynamic nature of the industry and the opportunity to acquire new skills and knowledge excite me.
- Explain your Final Year Project and your contribution to it.
Start the answer with the Title of your Final year project and explain it briefly by mentioning its main objective and purpose. Extend the answer by telling about your role and contribution to that project. Tell them about all your responsibilities, such as research, coding, design, testing, data analysis, etc. Explain your key achievements to showcase that you are a deserving candidate for the job opportunity. Tell how this experience allowed you to apply the theoretical knowledge you gained to a practical setting and how it helped your critical thinking, problem-solving, and teamwork skills.
- What are your salary expectations?
My primary focus is on gaining valuable experience and contributing to the success of the company. I am more interested in the opportunity to learn and grow professionally. Therefore, I am open to discussing a salary that aligns with industry standards for entry-level job opportunities in this field. I am confident that the compensation offered will reflect my skills and the value I bring to the organization.
Technical Interview Questions
Let’s discuss cognizant interview questions asked during the Technical Round.
- What is Proactive, Retroactive, and Simultaneous Update in the context of Database Management Systems (DBMS)?
Proactive Updates: Proactive Updates involve modifying the database before it enters real-world use.
Retroactive Updates: Retroactive Updates are changes applied to a database after it has been in operation in the real-world environment.
Simultaneous Updates: Simultaneous Updates refer to updates that are implemented in the database at the moment they become functional in the real-world environment.
- What is the fill factor in SQL and its default value?
The fill factor in SQL represents the percentage of data that fills each leaf-level page. SQL Server operates with a page size of 8K, which can accommodate one or more rows depending on their size. By default, the Fill Factor is set to 100, equivalent to 0. When the Fill Factor is 100 or 0, SQL Server maximizes the number of rows on each leaf-level page, resulting in little to no empty space.
- What is index hunting, and how does it contribute to improving query performance?
Index tuning involves optimizing a set of indexes to enhance query performance and reduce query processing time. It contributes to improved query performance through the following means:
Recommending optimal queries using the query optimizer.
Assessing the impact by examining factors like indexes, query distribution, and performance.
Streamlining databases to address a limited set of problematic queries.
- Define Root Partition in OS.
The root partition serves as the location for the operating system kernel and may also contain other essential system files that are mounted during the boot process.
- What are the determining factors for the necessity of a detection algorithm in a deadlock avoidance system?
Two key factors include the algorithm’s dependence on the frequency of deadlock occurrences during implementation and its impact on the number of affected processes.
- Define resident and working set.
The resident set represents the portion of the processed image currently residing in physical memory. It can be divided into subsets where one of these subsets is the working set, and it is the specific portion of the resident set necessary for execution.
Answers for some cognizant interview questions will be in coding form
- Write a program coding for finding the length of a string without using the string function.
Coding
#include <iostream>
#include <cstring> // Include the C string library for strlen function
using namespace std;
int main() {
char str[100];
cout << “Enter a string: “;
cin.getline(str, 100); // Read the input string with spaces
int len = strlen(str); // Use the strlen function to find the length
cout << “Length of given string is: ” << len << endl;
return 0;
}
- Write a code for printing the address of a variable without using a pointer.
Coding:
#include <iostream>
using namespace std;
int main() {
int x;
float y;
char z;
cout << “Address of x: ” << &x << endl;
cout << “Address of y: ” << &y << endl;
cout << “Address of z: ” << static_cast<void*>(&z) << endl;
return 0;
}
- State the steps to create, update and drop a view in SQL.
In SQL, a view is essentially a virtual table that draws data from one or more other tables, presenting it in a structured format resembling a real table with rows and columns.
To create a view, you can use the following syntax:
CREATE VIEW View_Name AS
SELECT Column1, Column2, Column3, …, ColumnN
FROM Table_Name
WHERE Condition;
For updating an existing view, you can use:
CREATE OR REPLACE VIEW View_Name AS
SELECT Column1, Column2, Column3, …, ColumnN
FROM Table_Name
WHERE Condition;
And to remove or drop a view:
DROP VIEW View_Name;
In the above queries, ‘Column1, Column2, …, ColumnN’ represents the names of the columns you want to include or update. ‘View_Name’ is the name of the view being created or modified, and ‘Table_Name’ is the name of the source table.”
Some cognizant interview questions will be in the form of an explanation.
- State the similarities and differences between SJF (Shortest Job First) and SRTF (Shortest Remaining Time First) CPU scheduling algorithms.
Shortest Job First (SJF) is a scheduling policy that prioritizes waiting processes based on their shortest execution time, also known as Shortest Process Next (SPN) or Shortest Job Next (SJN). It is a non-preemptive scheduling algorithm, meaning a process cannot interrupt the execution of another already running process.
The preemptive version of SJF scheduling is called Shortest Remaining Time First (SRTF). In SRTF, the next process in the queue with the shortest remaining execution time is selected for execution. When processes have equal arrival times, SRTF reverts to SJF scheduling.
Similarities:
- Implementing both SJF and SRTF can be challenging due to the unpredictability of process burst times.
- Both SJF and SRTF have the risk of causing process starvation, as lengthy processes may be indefinitely postponed if shorter processes are consistently introduced.
- When all processes are present in the ready queue, SJF and SRTF behave identically because no preemption occurs after processes join the ready queue.
Differences:
- Shortest Job First:
SJF operates as a non-preemptive algorithm.
SJF incurs lower overhead compared to SRTF.
- Shortest Remaining Time First:
SRTF operates as a preemptive algorithm.
SRTF incurs higher overhead compared to SJF.
- How does Dynamic Loading contribute to improving memory space efficiency?
Dynamic loading is a strategy where a program’s routines are loaded into memory only when they are actually needed, making it particularly effective for managing extensive codebases with rarely used components like error routines. All these routines are initially stored in a relocatable load format on the disk. The main program is executed after being loaded into memory. When one routine needs to call another, it first checks if the required routine is already loaded. If it’s not, a relocatable linking loader is employed to load the requested routine into memory and update the program’s address tables. The newly loaded routine then assumes control. This approach optimizes memory space utilization by loading code on demand.
- What is a Virtual File System Used for?
A VFS (Virtual File System) or Virtual Filesystem switch is a higher-level abstraction built upon a less abstract file system.
A Virtual File System (VFS) enables client applications to access different concrete file systems in a uniform way, allowing for seamless access to both local and network storage devices without requiring the client device to distinguish between them.
It serves as a means to connect Windows, traditional Mac OS/macOS, and Unix file systems, enabling applications to interact with files on these diverse local file systems without requiring prior knowledge of the specific file system being accessed.
A VFS establishes the interface between the kernel and a particular file system, simplifying the process of integrating support for new file system types into the kernel.
- What is Cache, and how does it work?
Caching is a method that involves storing multiple copies of frequently accessed data in a temporary storage area, known as a Cache, to enable quicker access. It preserves data in a temporary format for software applications, servers, and web browsers, reducing the need for users to download information each time they access a website or utilize an application.
Cached data is stored in a device’s memory, typically located close to the central processing unit (CPU). The primary cache level is integrated into the device’s microprocessor chip, followed by two secondary cache levels that feed the primary one. This stored information remains in the Cache until it reaches its time to live (TTL), indicating how long it should be cached or until the device’s disk or hard drive cache becomes full.
Data caching is commonly implemented in two ways: through browser or memory caching (where data is stored locally on the computer) and through Content Delivery Networks (where data is stored in geographically dispersed locations).
- What is Preemptive Multitasking, and how is it different from Cooperative Multitasking?
Preemptive Multitasking enables computer programs to utilize operating systems (OS) and underlying hardware resources collaboratively, allocating and managing computing time among processes based on predefined criteria. Another term for Preemptive Multitasking is time-shared Multitasking.
In cooperative multitasking, context switching from one process to another is never initiated by the operating system. Instead, context switches only occur when processes willingly relinquish control on a regular basis, become inactive, or encounter logical blocks. This cooperative approach allows multiple applications to run simultaneously, with all processes collaborating to facilitate the scheduling strategy.
- Define Plumbing/Piping in Linux or Unix.
Plumbing or piping is a method that involves taking the output of one program and using it as input for another. For example, instead of displaying a directory or drive listing on the main screen, you can pipe it to a file or send it to a printer for hard copy printing.
A pipe is a form of redirection used in Unix-like operating systems, including Linux, to transmit the output of one command, program, or process to another for further processing. Unix and Linux systems allow you to connect the standard output (stdout) of one command to the standard input (stdin) of another command using the pipe character ‘|’.
- List out the elements of a Processed image.
The elements of a processed image are given below.
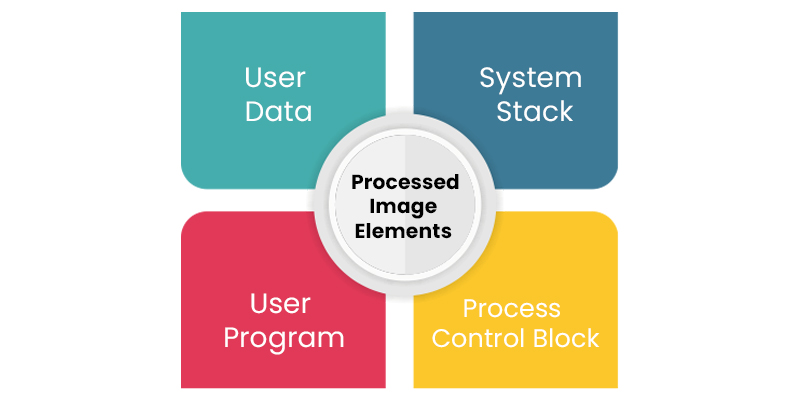
User Data: The User Data encompasses program data, the user stack area, and programs that are subject to modification within the user space.
User Program: A User Program consists of a set of instructions intended for execution.
System Stack: The system stack, in association with each process, comprises one or more Last In First Out (LIFO) stacks used to store parameters and calling addresses for procedures and system calls.
Process Control Block: The Process Control Block (PCB) contains essential information necessary for the operating system to manage operations.
- Define Trapdoor in OS.
A Trapdoor is a software/ hardware mechanism that enables the bypass of system controls. Malicious software is designed to grant unauthorized access to a computer system or network from a remote location, enabling an attacker on the internet to issue remote commands. Trap door software, in particular, monitors specific Transmission Control Protocol orUser Datagram Protocol ports for incoming orders.
- Define Translation Look-aside Buffer.
The TLB (Transaction Look-aside Buffer) is a specialized cache responsible for storing recently accessed transactions, including the most recently used page table entries. When the CPU is provided with a virtual address, it examines the TLB. If a page table entry is found (referred to as a TLB hit), the frame number is retrieved, and the actual address is constructed. In cases where a page table entry is not present in the TLB (known as a TLB miss), the page number serves as an index for accessing the page table. The TLB initially verifies whether the page resides in the main memory; if not, a page fault occurs, and the TLB is updated to include the new page entry.
- What is a bridge router?
A bridge router is referred to as a network device which functions as both a bridge and a router. The router forwards all other packets like a bridge and forwards only routes packets for known protocols.
Routers function at the network layer for routable protocols. In contrast, non-routable protocols operate at the data link layer. When routers operate as routers for routable protocols, they act as bridges for non-routable protocols by handling both routable and non-routable characteristics. Routers will connect devices in networking systems, which act as both a network bridge and a router in the internetwork.
- Define Exterior Gateway Protocol (EGP).
The EGP, which stands for Exterior Gateway Protocol is used to allow Internet gateways from the same or separate autonomous systems so that they can share network reachability information. EGP has 3 different purposes:
- To create a set of neighbors.
- To keep checking on the neighbors to see whether they are alive and reachable.
- To notify the neighbors about the networks that are accessible from their autonomous systems.
- What is a Network Virtual Terminal?
All Telnet clients and servers deliver data and commands that conform to a fictional virtual type called Network Virtual Terminal (NVT) rather than communicating in native languages. Network Virtual Terminal generally specifies a set of standards for sending and formatting data, which includes line termination, character set, and the way the Telnet session information is provided. A Telnet client can communicate in both its native language and Network Virtual Terminal. When a user enters information in their local terminal, the information will be translated into NVT, and the translated format will be sent to the network. Once this information is received by the Telnet server, it will convert it from NVT to the format that is required for remote hosts.
- Define Hamming Code.
Hamming code is defined as a set of error-correction codes that are used to detect errors and fix them. These errors can arise when data is transferred or stored from one source to another source. Redundant bites are known as the extra bits created and added to the data transferred information-carrying bits to make sure that there are no lost bits when transferring data. A parity bit appends to binary data to verify whether the total number of 1s is even or odd. Error detection occurs along with the parity bit. The hamming code is typically used by the additional parity bits to allow error detection.
- What is the use of Pseudo TTY?
A pair of Virtual Character devices, which is also known as Pseudo TTY or PTY, provides a bidirectional communication channel. The master slaves are at either end of the channel. The slave’s end in a pseudo-terminal provides an interface that is similar to that of a conventional terminal. A process connected to a terminal can open the slave’s end, which will be controlled by a program that has opened the master’s end. Whatever is written on the master’s end will be supplied to the process of the slave’s end of the pseudo-terminal. On the other hand, whatever is written on the slave’s end can be read by the process that has been linked to the master’s end. Applications that employ Pseudo-Terminals are Network login services, terminal emulators, etc.
- What is a BufferedWriter? What are the uses of flush() and close() functions?
BufferedWritter is referred to as a temporary data storage source that is used to make a buffered character output stream with a default output buffer size.
In Java, the flush() function of the BufferedWriter is employed to flush a character from the buffered writer stream to a file.
The close() of BufferedWriter is employed to flush the characters from the buffer stream and then to close it. If calling methods such as write() and append() after the stream is closed, an error will be generated.
- What is stored in stack and heap memory structures? How do they both relate to each other?
In the stack section of the memory, information about the nested method that calls down to the present program location is stored. This section also holds all the local variables and heap references that are defined in procedures that are currently running. The stack section allows the runtime to return from the method to know the address from which it was invoked and to remove all the local variables once the procedure exits.
Heap is used for dynamic allocation. When the user uses a new keyword to create an object, it will be allocated to the heap section.
- Illustrate whether it is possible to override and overload a static method in Java and to override a private method in Java.
In Java, it is not possible to override static methods since they are resolved at compile time. Overriding needs a virtual method that is resolved during the runtime since objects are only available during runtime. On the other hand, it is possible to overload a static method. There is no need for runtime in the case of Overloading. The number of parameters, the type of arguments, or even the sequence of arguments should be changed to alter the method signature.
It is not possible to override a private method since the subclass does not inherit the private methods that are needed to be overridden. A private method is not visible to external classes, and when it is called, the handling occurs during compile time based on type information rather than at runtime using the specific object’s information.
Some cognizant interview questions will be in the form of differentiation.
- Differentiate between RSA (Rivest, Shamir, Adleman) and Digital Signature Algorithm (DSA)
RSA
- It is a Cryptosystem algorithm.
- The RSA algorithm finds its application in secured data transmission.
- RSA implements the mathematical concept of factorization of the product of two large prime numbers.
- When compared to DNS, RSA is slower in Key generation.
- When compared to DNS, RSA is slower in decryption but faster in encryption.
DNS
- It is a Digital signature algorithm.
- The DSA finds its application in the digital signature and its verification.
- DNS implements the concept of modular exponentiation and discrete logarithm.
- When compared to RNS, DSA is faster in key generation.
- When compared to RSA, DSA is faster in decryption but slower in encryption.
Cognizant interview questions in the Technical round may also come in the form of code with output.
- Explain whether it is possible to «resurrect» an object that was eligible for garbage collection in Java.
The Garbage Collector (GC) is responsible for invoking the finalize method on an object once it becomes eligible for garbage collection. This is because the finalize method can be used only one time, and the Garbage Collection (GC) marks the object as a finalized object and sets it aside until it’s time for the next cycle.
Technically, by assigning an object to a static field, it is possible to resurrect it in the finalized method. The object would turn ineligible for Garbage Collection and will present GC to collect it in the next cycle.
On the other hand, the object will be marked as a finalized object so that the finalised method will not be called when the object turns eligible again. The resurrection method can be used only once.
Coding
import java.util.ArrayList;
public class ObjectResurrectionExample {
private int num;
public ObjectResurrectionExample(int num) {
this.num = num;
}
static final ArrayList<ObjectResurrectionExample> ar = new ArrayList<>();
protected void finalize() throws Throwable {
System.out.println(“Object with num=” + num + ” is ready for finalization.”);
ar.add(this);
}
public String toString() {
return “Element(” + “number = ” + num + ‘)’;
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 3; i++) {
ar.add(new ObjectResurrectionExample(i));
}
for (int j = 0; j < 5; j++) {
System.out.println(“Objects in the ArrayList: ” + ar);
ar.clear();
System.gc();
Thread.sleep(500);
}
}
}
Output
Objects in the ArrayList: [Element(number = 0), Element(number = 1), Element(number = 2)]
Object with num=2 is ready for finalization.
Objects in the ArrayList: []
Object with num=1 is ready for finalization.
Object with num=0 is ready for finalization.
Objects in the ArrayList: []
Objects in the ArrayList: []
Objects in the ArrayList: []
- Define Monkey Patch in Python.
In Python, Monkey patches are known as the dynamic or runtime alterations of a class. It is possible to change the behavior of the code during the runtime.
Coding 1:
# m_alternative.py
class A:
def func(self):
print(“Alternative func() is called”)
# Usage
if __name__ == “__main__”:
obj = A()
obj.func()
The following coding contains the above coding (m) for changing the behavior of the func() during the runtime by assigning a new value.
Coding 2
# m_alternative.py
class A:
def func(self):
print(“Original func() is called”)
def monkey_func(self):
print(“Monkey func() is called”)
# Usage
if __name__ == “__main__”:
obj = A()
obj.func() # Calling the original func() method
# Replacing address of “func” with “monkey_func”
A.func = monkey_func
obj = A()
obj.func() # Calling the monkey_func() method
Output
Original func() is called
Monkey func() is called
- Write a programming code for adding two numbers without using arithmetic operators.
Coding:
#include<stdio.h>
int Addition(int a, int b)
{
if (b == 0) {
return a;
} else {
return Addition(a ^ b, (a & b) << 1);
}
}
int main() {
int num1, num2;
printf(“Enter two numbers: “);
scanf(“%d %d”, &num1, &num2);
int sum = Addition(num1, num2);
printf(“Sum of %d and %d is %d\n”, num1, num2, sum);
return 0;
}
In the above programming code, we use a recursive approach to add two numbers without arithmetic operators. The Addition function recursively performs the addition by using bitwise XOR and bitwise AND operations to simulate addition and carry, respectively. The program takes two input numbers from the user and then calculates and displays their sum.
- Write a programming code for printing numbers from 0 to 100 in C++ without the use of loop or recursion.
Coding:
#include <iostream>
using namespace std;
template<int start, int end>
class PrintRange {
public:
static void display() {
if constexpr (start <= end) {
cout << start << endl;
PrintRange<start + 1, end>::display();
}
}
};
int main() {
const int start = 0;
const int end = 100;
PrintRange<start, end>::display();
return 0;
}
In the above programming code, we use a template class PrintRange to print numbers within a specified range (from start to end). The program prints numbers from 0 to 100 without using loop and recursive, as requested.
In conclusion, the cognizant interview process typically consists of several rounds, including technical interviews and HR interviews. The technical interviews often focus on your knowledge of programming languages, data structures, algorithms, and domain-specific skills. The HR interviews aim to evaluate your interpersonal skills, problem-solving skills, and cultural fit with the company. With the help of the above-mentioned sample questions and answers, you can prepare well and excel in your interview.

